前言:
写这篇文章主要是因为最近使用GPT的API搭建本地大模型的时候。
使用到了语音部分处理相关的内容。
而在语音处理当中,其中涉及到的一个点就是ffmpeg。
ffmpeg是一个非常强大的工具,可以帮助我们轻松地处理音频和视频文件。
在使用Python调用GPT的API搭建本地大模型的过程中,我需要使用ffmpeg来处理语音部分的相关内容。

我需要使用ffmpeg将语音文件转换成所需的格式。
有时候,我们获取到的语音文件格式可能不符合我们模型的要求,这时就需要使用ffmpeg进行格式转换。
ffmpeg支持多种音频和视频格式的转换,使用起来非常方便。
我们只需要在命令行中输入相应的命令即可完成格式转换。
此外,我还需要使用ffmpeg对语音文件进行剪辑和拼接。
有时候,我们可能只需要语音文件中的某一部分,或者需要将多个语音文件拼接成一个完整的文件。
这时,我们可以使用ffmpeg提供的剪辑和拼接功能。
通过指定开始时间和结束时间,我们可以轻松地剪辑出所需的语音片段。
而拼接多个语音文件则更加简单,只需要将它们按照顺序输入到ffmpeg中即可。
此外,ffmpeg还可以帮助我们调整语音文件的音量和速度。
有时候,我们可能需要调整语音文件的音量,使其更加适合我们的需求。
ffmpeg提供了音量调整的功能,我们可以通过指定音量增益来实现音量的调整。
同时,ffmpeg还可以帮助我们调整语音文件的速度,使其变快或变慢。这在对语音进行预处理时非常有用,可以帮助我们更好地处理语音数据。
在使用Python调用GPT的API搭建本地大模型的过程中,ffmpeg起到了非常重要的作用。
它帮助我们处理语音部分的相关内容,包括格式转换、剪辑拼接、音量调整和速度调整等。
通过使用ffmpeg,我们可以更加方便地处理语音数据,提高模型的性能和效果。
下面,是ffmpeg的安装教程:
1.官网下载ffmpeg
进入Download FFmpeg网址,点击下载windows版ffmpeg(点击左下第一个绿色的行)

在release builds第一个绿框里面选择一个版本下载。

2.配置
下载完成后解压该压缩包:

单击进入ffmpeg,会出现如下界面:

在bin文件里会有三个exe文件,复制此时的地址


打开电脑设置,在属性里面点击高级系统设置,点击系统:

找到关于:

下拉,打开高级系统设置:

打开环境变量:
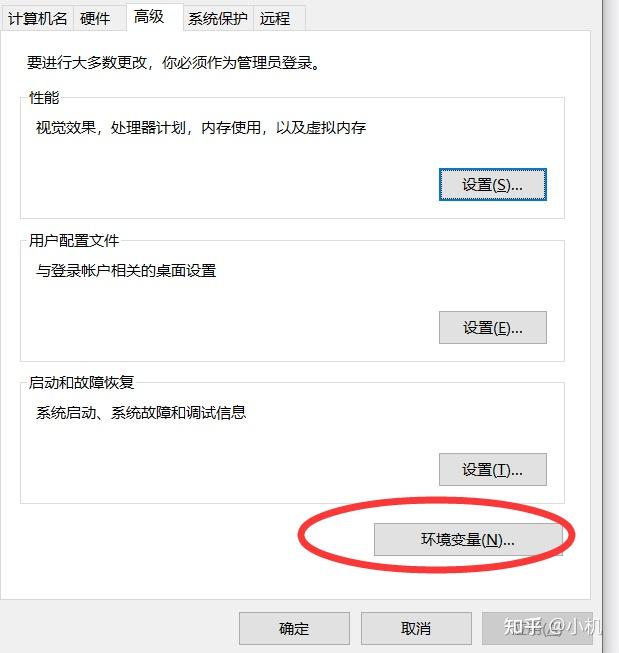
在系统变量中找到Path:

双击打开,点击新建:

出现:

再把最开始复制的地址黏贴进来,点击确定:

然后再连点三个确定。
保存完毕后,打开任意shell 输入ffmpeg -version,如果正常输出版本号则表示安装成功。

转自:https://zhuanlan.zhihu.com/p/692019886
还没有评论,快来抢沙发!